

Et studie fra Københavns Universitet slog tidligere på året fast, at ChatGPT er præget af amerikanske normer og et amerikansk verdenssyn. Nu har forskere i henholdsvis USA og Storbritannien dokumenteret, at sprogmodellerne i det hele taget har indbyggede politiske holdninger.
Konservativ AI?
Lad os lige starte med at slå fast, at sprogmodeller i sig selv ikke er politiske. Det vi snakker om når vi siger, at de udviser politiske holdninger er, at de data, de er trænet på, har en skævhed enten mod venstre eller mod højre på det politiske spektrum.
Og dem, der siger det er forskere fra henholdsvis University of Washington, Carnegie Mellon University og senest University of East Anglia i Norwich, England. Forskerne fra Carnegie Mellon fandt blandt andet frem til, at ældre modeller, som BERT-modellerne, ofte var mere konservative i deres svar, hvor fx GPT-modellerne var mere venstreorienterede. Baggrunden for forskellen ligger blandt andet i, hvor BERT modellerne er trænet på bøger, så er GPT-modellerne i høj grad trænet på materiale fra internettet.
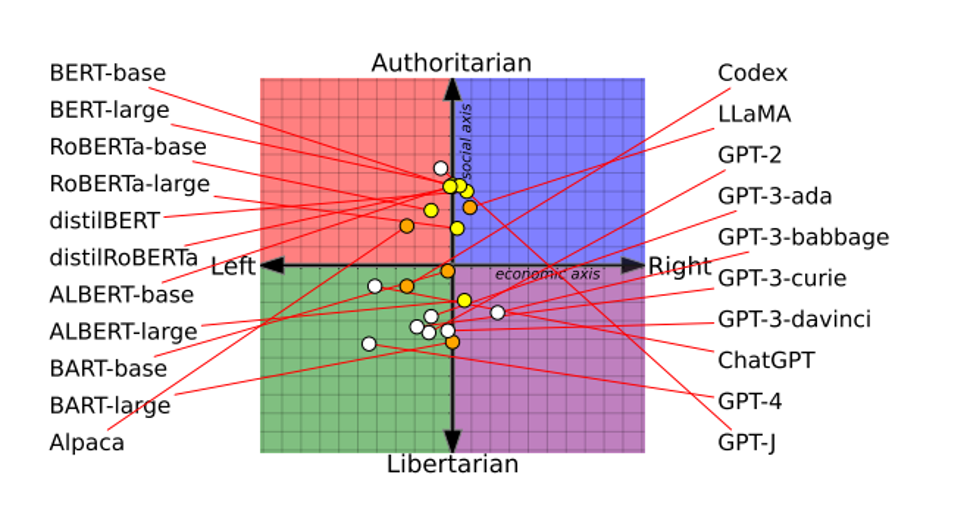
Undersøgelsen placerer Meta’s LLaMA som lidt mere autoritær og højreorienteret end GPT-4, der i sin nyeste og mest opdarede version var mere økonomisk og socialt venstreorienteret.
I den seneste undersøgelse fra University of East Anglia fandt man, at ChatGPT’s venstreorienterede tendenser faktisk strakte sig på tværs af flere lande. I Storbritannien foretrækker ChatGPT Labour, i USA det Demokratiske Parti og i Brasilien foretrækker den præsident Lula da Silva, fra Arbejderpartiet.
Følsomme venstreorienterede
I det amerikanske studie undersøgte de sprogmodellerne på tre niveauer af modellernes udvikling. På første niveau bad man 14 modeller besvare 62 politisk betingede spørgsmål med enig eller uenig. Det var her man først kom på sporet af modellernes politiske bias.
På andet niveau to man to specifikke sprogmodeller og trænede dem yderligere på nyheder og sociale medier. Resultatet var, at modellerne blev endnu mere udpræget enten højre- eller venstreorienterede.
På det tredje niveau fandt man at ”venstreorienterede” modeller var mere følsomme overfor såkaldt hate-speech mod etniske eller religiøse grupper og seksuelle minoriteter, hvor de ”højreorienterede” var mere følsomme overfor hate-speech rettet mod kristne, hvide mænd. De ”venstreorienterede” var også bedre til at identificere fake news fra højreorienterede kilder og de ”højreorienterede” var bedst til at finde fake news fra venstreorienterede kilder.
Den politiske bias og den politiske polarisering, som tallene afspejler forværres i modeller, der er trænet efter valget af Donald Trump til præsident i 2016, viser undersøgelsen fra Carnegie Mellon University.
”Polariseringen i samfundet bliver faktisk også afspejlet i modellerne,” siger forskeren Chan Park fra Carnegie Mellon.
Det er de sidste data, om at modellerne skelnede mellem forskellige kilder til misinformation, der mest overrasker Professor Anders Søgaard fra Datalogisk Institut ved Københavns universitet.
”De finder en markant sammenhæng mellem modellernes politiske overbevisning og deres performance i den sidste øvelse. Det har jeg ikke set før,” siger Anders Søgaard til Videnskab.dk.
Politiske data radikaliserer.
Undersøgelserne viser, at det ikke er nok bare at rense træningsdata for bias. For det første er det meget svært fuldstændig at rense træningsdata. For det andet har modellerne, som bekendt, en tendens til at opfinde informationer, hvis den ikke lige har de korrekte oplysninger. Det gør det også svært at bedømme, hvad ligger i data og hvad skyldes hallicunationer.
Samtidigt fremgår det af studierne, at opdatering af træningsdata og videre træning på nyere data forværrer bias – særligt på det politiske område. Man kan sige, at modellerne radikaliseres. Forskerne anerkender, at deres metode ikke er perfekt og de har da heller ikke fået adgang til de nyeste modeller til deres forskning. Ikke desto mindre viser undersøgelserne, at der et problem og at dette problem bliver værre.
Den tendens vi ser i øjeblikket er, at sprogmodellerne ændrer den måde vi søger information på nettet og det vil sige, at særligt politiske holdninger hos brugerne kan præges, hvis de får deres politiske informationer via sprogmodellerne.
Vi ser også, at virksomheder i stigende grad integrerer AI-modeller i deres produkter og services og de skal derfor være meget opmærksomme på de bias, der er født ind i disse modeller.
Et element i at modvirke disse bias er at uddanne brugeren i systemerne i at disse skævheder eksisterer og at de ikke altid er åbenlyst i de svar systemerne giver. Derudover kan virksomhederne bag sprogmodellerne, Meta, OpenAI, Google osv., skal være mere transperante omkring hvilke data, de træner modellerne.
De skal også være mere åbne omkring hvilke mennesker, de har til at foretage den del af træningen kadet ”reinforcement learning with human feedback” (RLHF). Igennem RLHF-processen, hvor systemerne får feedback fra menneskelige testere, bliver systemerne mere opmærksomme på menneskers værdier og tankemønstre.
Medlem
80 kr./måned
Bliv medlem på PatreonStøt AI-Portalens uafhængige journalistik om AI, magt og samfund.
Inkluderet i medlemskabet:
- Månedligt nyhedsbrev
- Invitationer til online og fysiske events om AI
- Adgang til optagelser og opsamlinger fra møder og foredrag
- Rabat på events
- Invitation til månedligt online redaktionsmøde
Medlemskab administreres via Patreon.
Vi laver journalistik om AI, fordi udviklingen går hurtigere end den offentlige samtale.
På AI Portalen forsøger vi at skabe overblik, perspektiv og kritisk indsigt i en teknologi, der allerede former alt fra arbejdsmarkedet til demokratiet — ofte uden at nogen bremser op og forklarer, hvad der foregår.
Hvis vores artikler hjælper dig med at forstå AI lidt bedre, så overvej at støtte arbejdet.
Et medlemskab gør én ting mulig: at vi kan blive ved med at undersøge, dokumentere og forklare, hvordan AI påvirker Danmark — uden investorer, uden PR-interesser og uden at jage hype.
Bliv medlem og vær med til at styrke uafhængig journalistik om AI.


Follow Me